How We Use Cassandra at Kit


What is Cassandra?
Simply put, Apache Cassandra is a NoSQL distributed database. It’s a lightweight, open source datastore commonly used for storing vast amounts of data that require a high amount of availability. Cassandra databases are distributed and this prevents data loss from any one system’s hardware failure. A Cassandra cluster is a collection of nodes, which are single instances of Cassandra in a ring formation. The nodes communicate with each other as peers to resolve data.
How do we use Cassandra?
At Kit, we sent 22 billion emails just last year. We save every email-related event for every email we’ve sent since 2013 and we’ve kept those all in hot storage in our Cassandra cluster. Cassandra is the backbone of our highly critical email pipeline and provides confidence that we’re not sending the same email. This means that for a single email sent from our platform, we write multiple events to Cassandra helping our cluster grow quickly to 40TB.
In addition to events data about emails, we store information in Cassandra that powers engagement reports for our creators and profile data for their subscribers. This mountain of data, the growing cost of it, and understanding the way creators interact with it has initiated important data retention conversations at Kit over the last year.
The Data
Currently, we use SendGrid to send about 90 million emails per day. We first write to our Cassandra cluster when a creator initially sends out an email. Then we utilize SendGrid webhooks to record when the email is delivered, when a subscriber opens it, clicks on a link, unsubscribes, or reports the email as spam. Behind the scenes, SendGrid may also experience a deferral, drop, bounce, or block. We record each one of these events and considering a single email could be deferred 15 times before it’s delivered, this quickly becomes a huge amount of data. On average, we write about 5,600 records/second every day, peaking at ~32,000 records/second. And latency is critical in email sending; we read this data at an average of 8,600 requests per second.
Average reads per second in one week 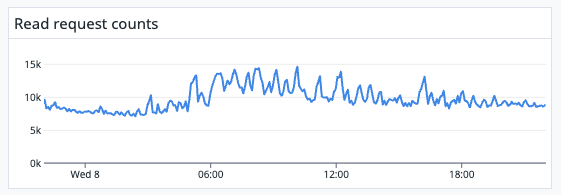
Average writes per second in one week 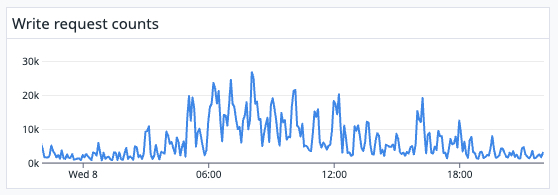
Data: The Cost
The amount of money we spend to keep our Cassandra cluster in two i3.2xlarge AWS EC2 instances is one thing. The number of engineering hours spent on maintaining, scaling, and repairing the Cassandra cluster is entirely another thing. The operational overhead of our Cassandra cluster is a major pain point for us as our infrastructure team is quite small and our data problems are quite big.
Every three months, our growth requires us to scale out the cluster by adding six additional nodes. This adds complexity to managing the cluster, requires us to rebalance it, and inches us closer to the maximum that a Cassandra cluster can handle: 100 total nodes. Rebalancing the data monthly across servers currently takes ten days which means we’re running maintenance on this database ~30% of the time.
Data: How Creators Use It
The biggest way creators use the data stored in Cassandra is simply trusting us to send their emails. The SendGrid webhook event data we save in Cassandra facilitates that confidence that creators have come to depend on.
In addition to this, some creators use our Cassandra-powered engagement reports to better understand subscriber engagement and interaction with their emails. We’ve recently run experiments to capture the rate at which creators use some of this data and the results have had an impact on our data retention discussions and migration plans.
Where Do We Go From Here?
The pain points we’re encountering with Cassandra aren’t unique to Kit, our schema, or our data. This state of unpleasant maintenance tasks and cumbersome overhead effort is common for organizations that horizontally scale their Cassandra clusters quickly in the way we have. This current solution was implemented quickly in 2019 and has served us well for many years through many many emails. Still, our team has been proactive on preparing for the runway on this solution to end and have been discussing a number ideas including using cold storage for older data.
To prepare for the longer term as we get closer to the 100 node limit, our team is actively working on a proof of concept to replace our Cassandra cluster with AWS Keyspaces. This is an option we’ve been considering after learning about Intuit’s migration from Cassandra to Keyspaces. Their approach to migrating a similarly sized cluster with critical financial data over to AWS Keyspaces has been massively helpful in carving out a feasible path forward for Kit. You can watch the folks from Intuit and AWS presentation on this from AWS re:Invent 2022. The potential move to Keyspaces is anticipated to alleviate the majority of maintenance efforts as AWS manages and scales the datastore as part of the service.
Cover image includes logos for Kit and Apache Cassandra