The Effect of Database Write Latency on Performance

MySQL at Kit
MySQL is the oldest data store that Kit uses and is the backbone for most of our application. It powers everything from user logins to subscriber filtering. We host MySQL on AWS through RDS. As of July 2023, our MySQL database is 13.75TB running in High Availability on a db.r6g.16xlarge instance in the us-east-2 (Ohio) region. When MySQL has a problem, we feel it throughout the rest of our application. This post details how an AWS outage led to performance problems at Kit and how we got past them.
December 24, 2022
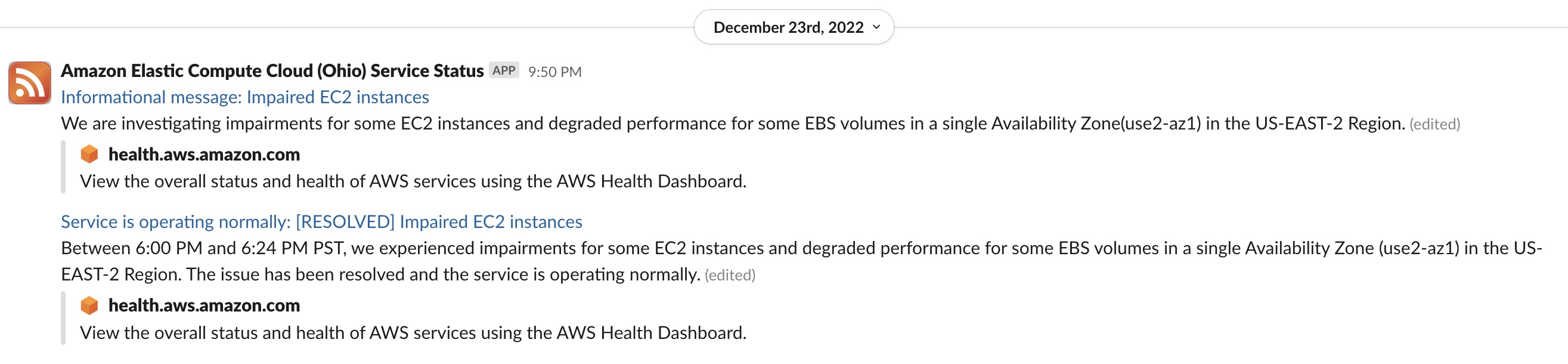
We got an alert on Slack from our AWS RSS feed on December 23, 2022, at 9:50 pm EST saying that some EC2 instances and EBS volumes had degraded performance in the use2-az1 availability zone. Coincidentally, that’s where our MySQL primary lives. Kit hosts our servers in multiple availability zones, so we didn’t pay much attention to it initially because any hosts with problems could be terminated and replaced painlessly. Additionally, AWS marked the event as resolved and said the degradation only lasted 24 minutes.
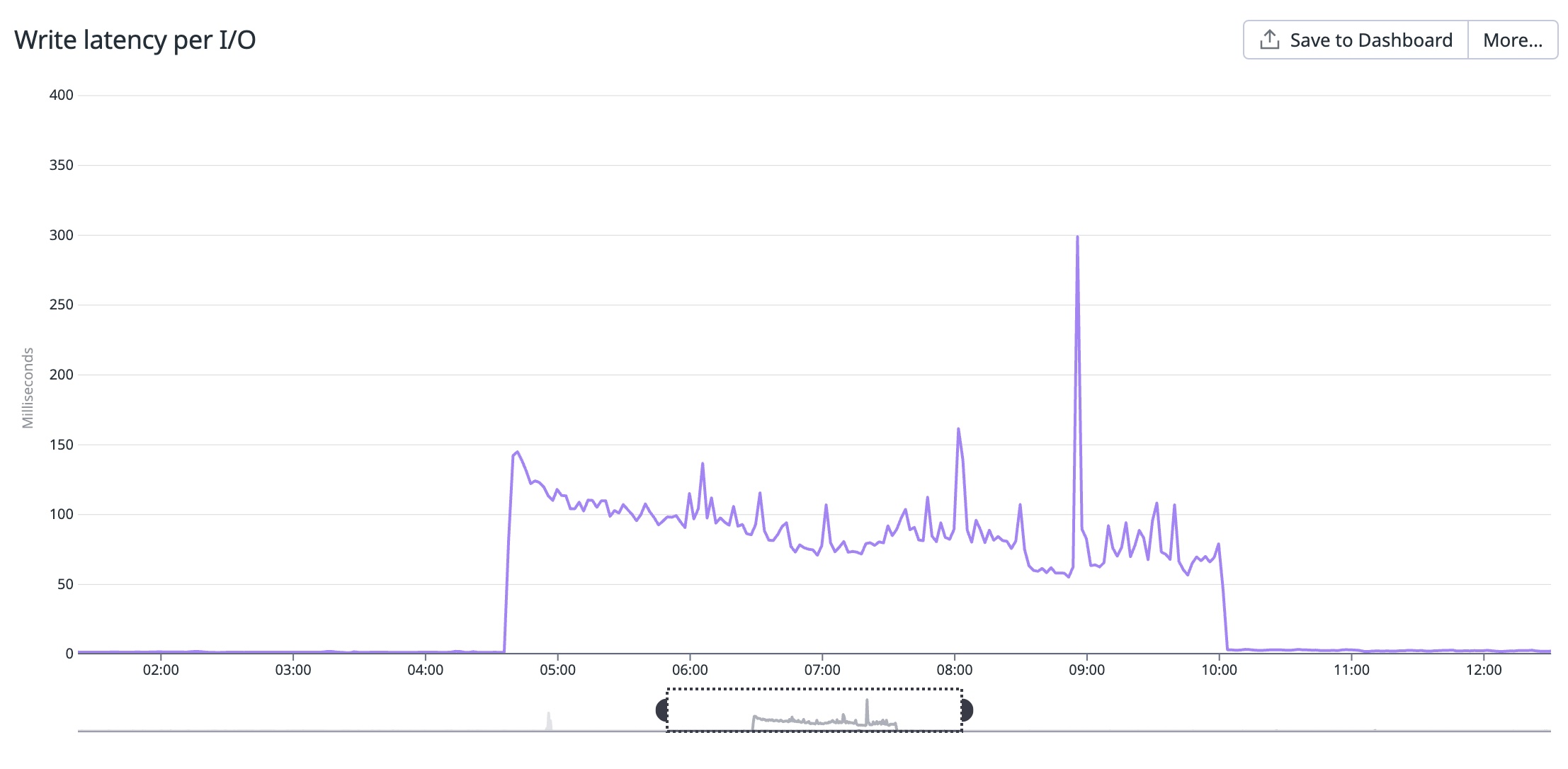
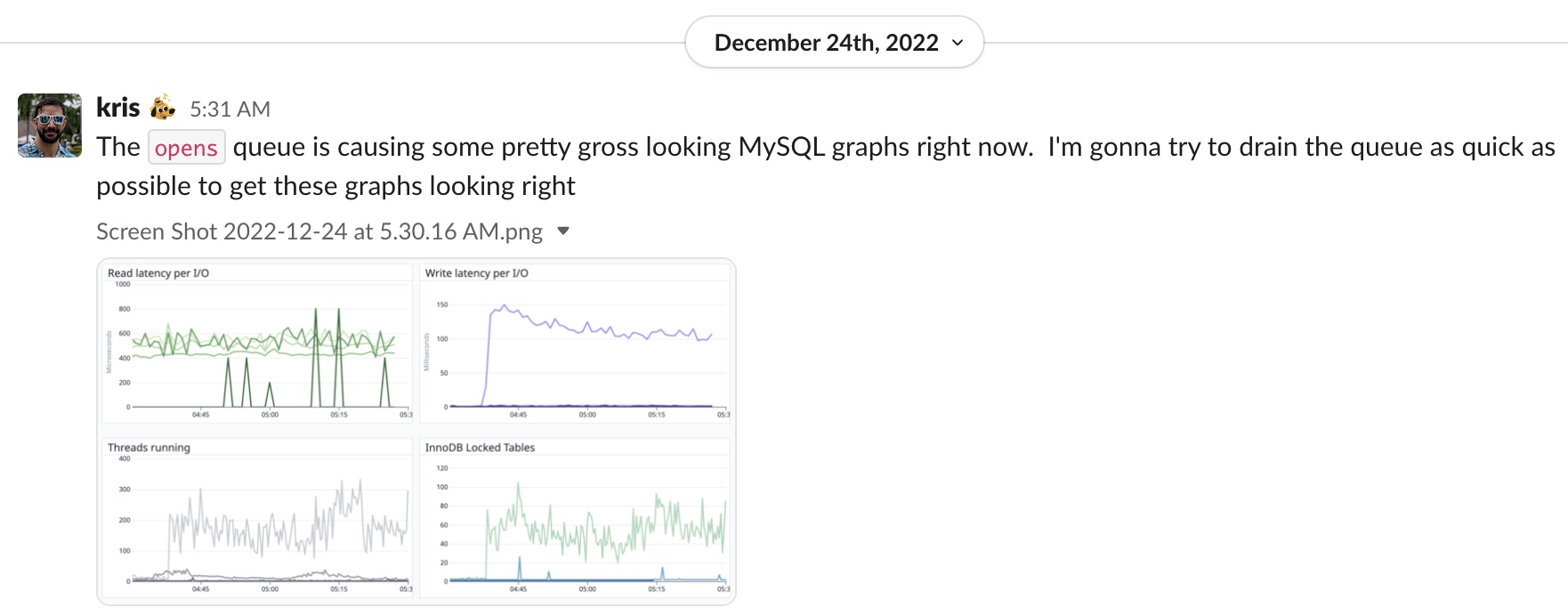
However, on December 24, 2022, at 5:20 am EST, we got our first page saying that the number of MySQL threads running spiked 100x from 9 to 900. 5 am on Christmas Eve is a very low volume time for Kit, so to see such a dramatic increase in running threads was concerning.
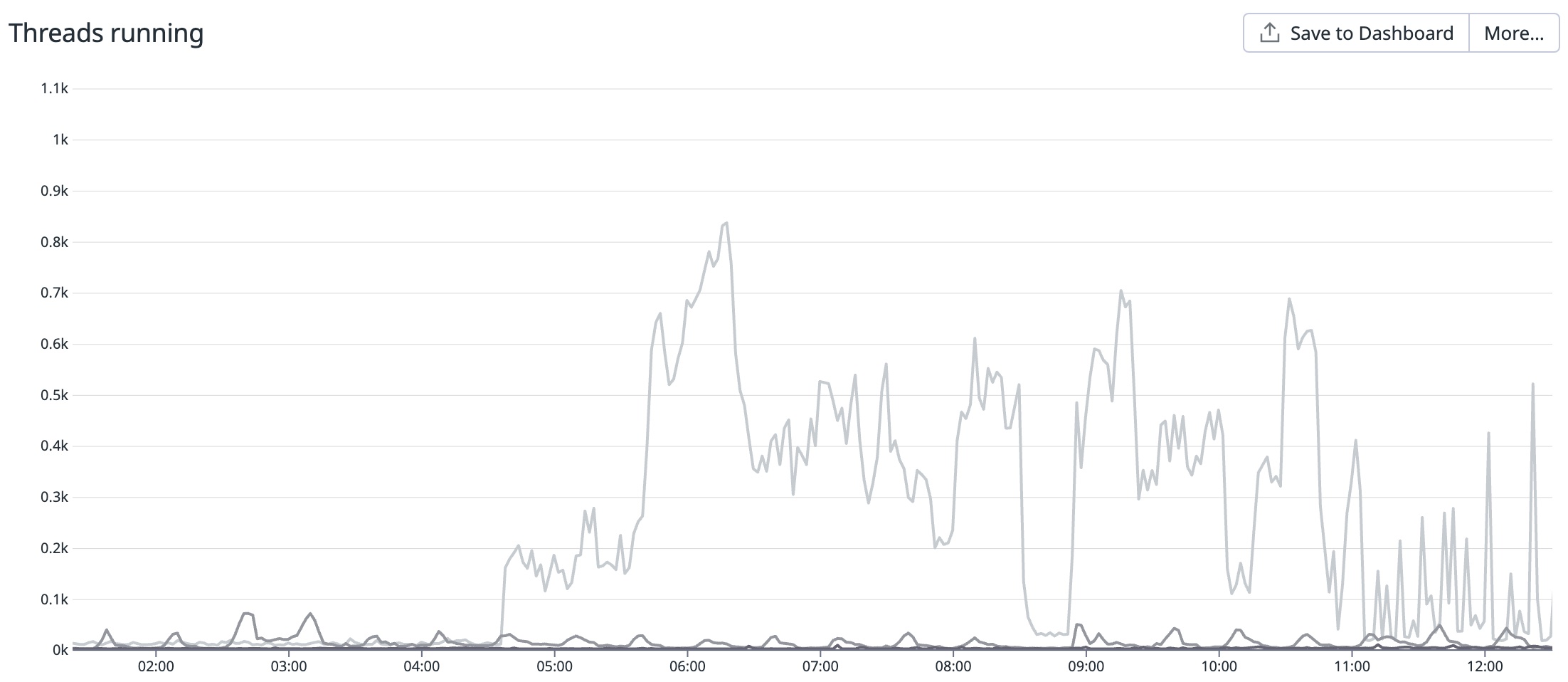
Kit is also a heavy Sidekiq user. We process about 5 billion sidekiq jobs per month. That averages 166 million jobs per day, 6.9 million jobs per hour, 115,000 jobs per minute, or about 2000 jobs per second. Most of these Sidekiq jobs interact with MySQL in some way. When MySQL has a problem, it impacts our ability to process jobs. Because Kit processes so many jobs, the first thought we have when performance degrades is that we shipped some code that had a negative impact on one of our queues. That was where I started triaging, and because it was 5 am, I wasn’t at my sharpest, and I incorrectly started looking at one particular queue that was backed up more than any other queue.
Digging Deeper
I was unable to find anything related to the queue in question that could cause such a dramatic degradation in performance, and upon further digging, I found out that our write latency on RDS MySQL had increased over 100x from about 1.5ms to about 150ms and even as much as 300ms.
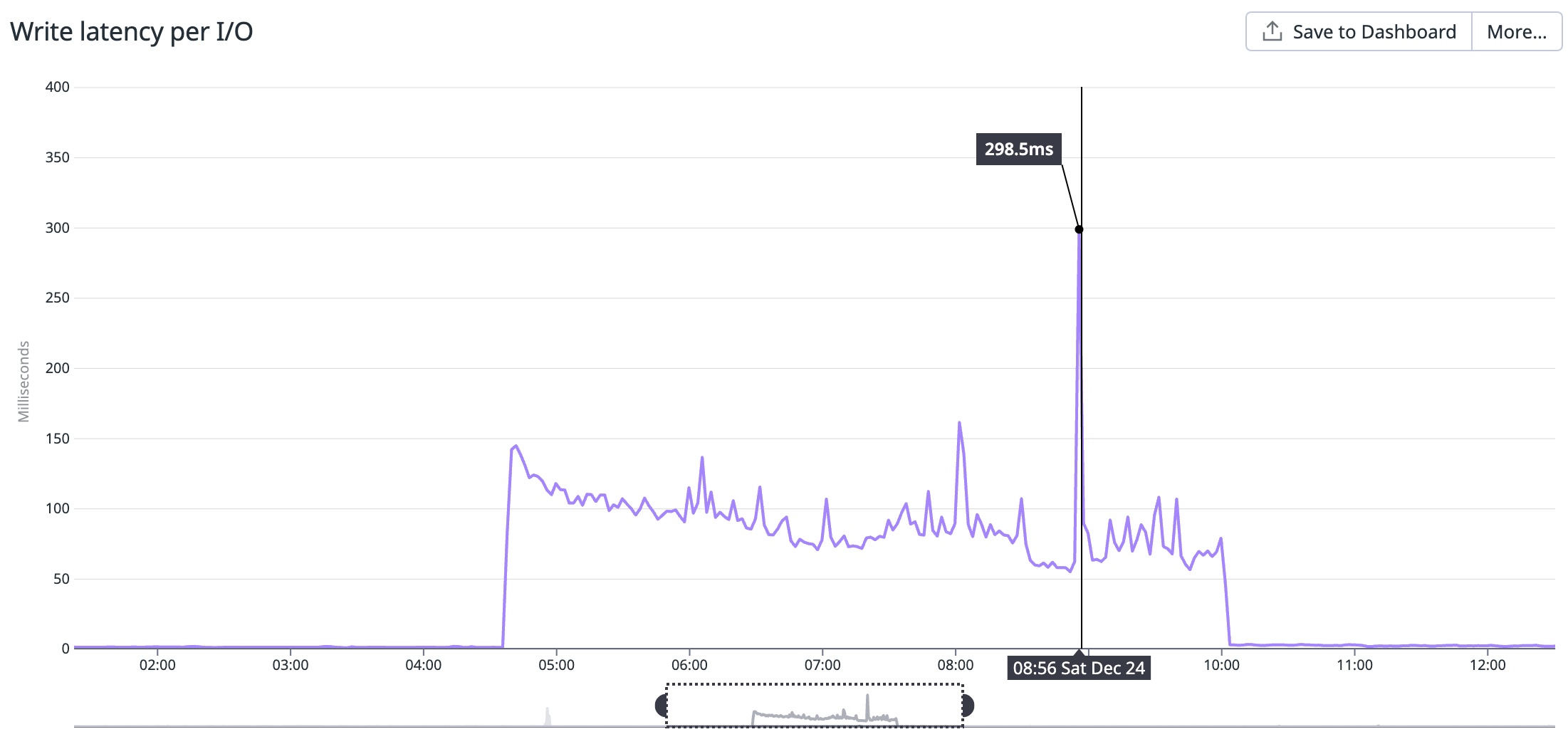
The conclusion that we ended up at was that the poor write performance on MySQL was preventing us from processing Sidekiq jobs as fast as we usually do. This was bad news for a lot of reasons. Our queues were backing up. Processing over 150 million jobs daily also means we enqueue 150 million jobs daily. Since Sidekiq is backed by redis, we are limited by redis memory. If we enqueue jobs faster than we can process them, redis will eventually run out of memory and crash. If we lose redis, we lose the jobs enqueued, and that’s the worst-case scenario. We had to do something quickly because redis was running out of memory quickly. We had two options:
- Move our Sidekiq redis to an instance with more memory, or
- Figure out how to improve MySQL write latency so we could drain the jobs we already had enqueued
Option 1 was a short-term solution and also a terrifying one to try. It was early in the morning, and stress was building which is not an ideal place to be when making such big server moves.
Option 2 was the long-term solution, but since we couldn’t figure out why our write latency had degraded in the first place it wasn’t an easy solution either.
Resolution
The first attempt we made at recovering write performance was to fail over the database to the standby. Three hours into the incident, at 8:33 am EST, I attempted to fail over the database. I knew this would cause unexpected downtime, but it was the only thing I could think of to try. However, to my surprise, we never had downtime, and it was because the failover failed. We were still stuck on the original database instance, and write performance was still in the hundreds of milliseconds.

RDS is built on top of EBS. After shrugging off the original EBS alert we got from the AWS RSS feed 12 hours prior we pieced together that MySQL was struggling because of that same EBS degradation. If we wanted to improve write performance, we had to figure out how to get the backing EBS volumes into a working state again.
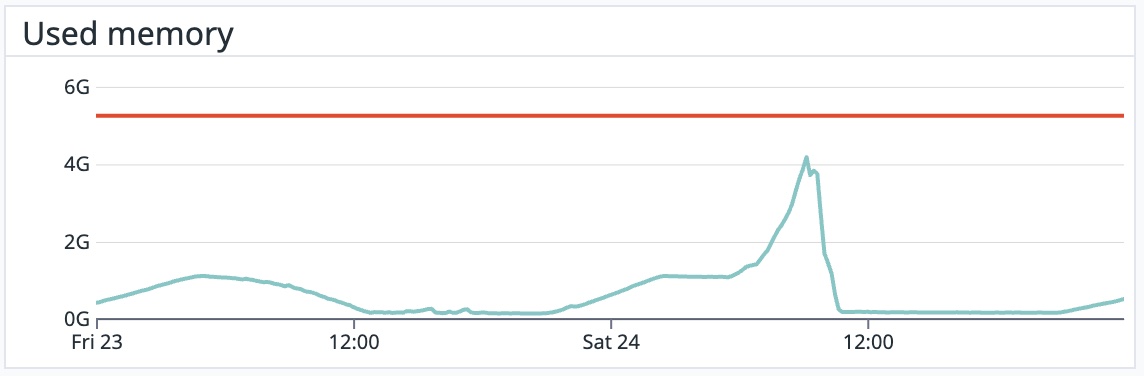
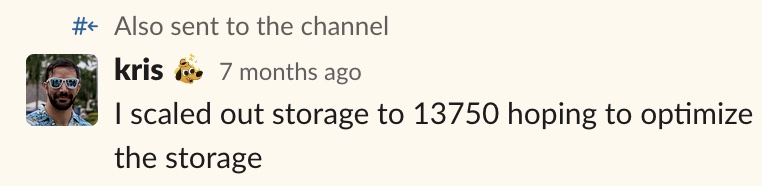
The last idea, and the one that solved our issue, was scaling out the storage capacity of the RDS instance. We scaled from 12.5TB of storage to 13.75TB of storage, and in doing so, we could go through the RDS state of “optimizing storage,” where AWS moves some EBS volumes around to optimize storage. After the scale-out, our write latency returned to its original performance levels of between 1 and 2 ms.
Conclusion
Once our write latency returned to normal, our Sidekiq jobs processed normally again, the queues drained, redis memory returned to safe levels, and everything was ok. It was a scary event, but our service never stopped despite moving slowly. Understanding how RDS works, how EBS works, and how RDS and EBS affect Kit were good lessons to learn and reinforce for us to continue building the stable and resilient service that we have.
AWS multi-AZ is good for high availability and data durability. Replication happens synchronously, ensuring that data is consistent and there is no data loss in case of an incident. However, writing data synchronously has the downside of needing to commit every transaction to the standby, not only the active, as it does in a single-AZ deployment.
An EBS interruption on the standby server caused this incident, triggering an EBS volume replacement. In normal circumstances, the extra latency overhead the synchronous replication adds is acceptable. However, the EBS volume was in a degraded state while the volume was being replaced. This made the write latency even worse. In large databases like ours, recovery times are higher, while in small databases, the impact of incidents like this could’ve been negligible.
If we had our RDS server in a single AZ, this incident wouldn’t have impacted us. However, if the impacted AZ was where the single-AZ RDS server was running, we would have had a severe downtime for several hours instead of only write performance degradation. These types of tradeoffs need consideration when deciding how to deploy production RDS instances.
Here is the postmortem that AWS sent us:
Here was the internal team investigation:WriteLatency was increased between 2022-12-24 09:34 UTC and 2022-12-24 14:56 UTC.
replaceSecondaryHostAndVolumesTask occurred due to LSE that occured on 2022-12-24 at 02:12:47 UTC. When replaceSecondaryHostAndVolumesTask is in progress, the snapshot of the primary is taken and restored in secondary. The cx initiated a failover but the failover was timed out because the primary was not in-sync with the secondary when the failover was requested.
Around 9.30h UTC there was a sudden increase in the write I/O latency on RDS MySQL which increased from 1-2ms to 140ms. The reason behind this was due to “replaceSecondaryHostAndVolumesTask” WF, the secondary host and volumes were replaced. Since the secondary instance volumes were rebuilt with the snapshot of the primary instance volumes, the secondary volumes had “first touch penalty”, which caused elevated write latency. Also, the customer workflow showed that between 2022-12-24 09:38:03 UTC and 2022-12-24 14:59:35 UTC these issues occured. The WriteLatency was spiked because the secondary was in progress to sync up with the primary.
Around 13.30h UTC the customer tried to initate a failover to the RDS instance with no luck and the operation timed out. The reason behind this was due to the secondary host not being in-sync until 2022-12-24 14:59:35 UTC, the failover could not complete correctly. The failover will not occur if the instance is not in-sync.
Around 14.30h UTC the customer decided to scale out their storage by 10% (from 12500GB to 13750GB) and around 15.05h UTC their database was stable again and the write latency went to its normal threshold.